Expanding the Boundaries of ChatGPT with LangChain - Part One
You have likely noticed a massive influx of applications that
claim to use artificial intelligence. Many of these applications are built
using a framework called LangChain. In this post, we’ll provide a basic
introduction to this technology and explain why it can be beneficial in your
daily taskings.
Let’s start off with “normal” ChatGPT usage. Most users go to the ChatGPT website, ask ChatGPT to do something, and read the response. The technology is both awe-inspiring and currently limited. It’s limited by not having internet access, access to recent information, or the ability to incorporate the user’s files or data into its workflow. It’s also limited by the size of how big prompts or answers can be. The “normal” usage of ChatGPT looks like this.
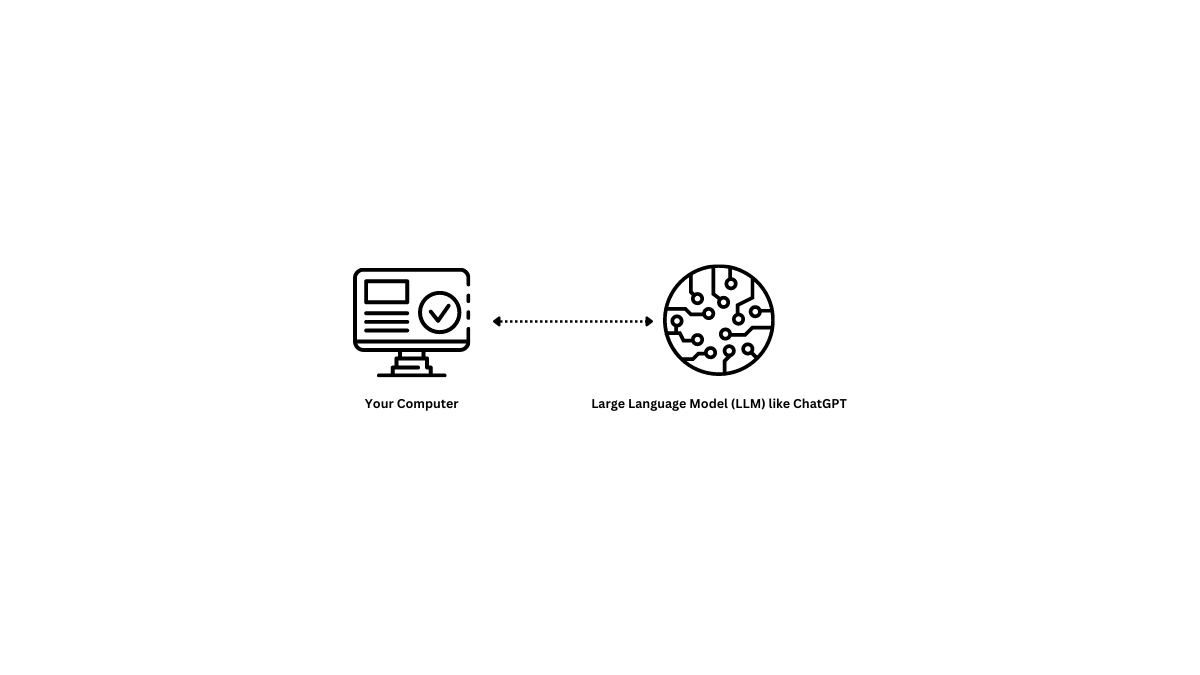
You can do some amazing things with this basic model, but think of how many things aren’t incorporated here and the potential that they could unlock if they were.


Let’s take a look at an example. I asked ChatGPT (GPT-4) what teams are most likely to win the 2023 baseball world series.

It states that it doesn’t have any knowledge later than September 2021 and lists a few teams that have historically been good. Not mentioned in the team that is currently favored to win the world series, the Atlanta Braves.
Now, here are the results of some Python code I wrote where
I ask GPT the same question (using the API, not the web interface), but I use LangChain
to give GPT access to the current world series championship odds according to
MGM.

Now this is getting interesting!
We can also use LangChain to access files on our computer,
in a database, etc and provide that context to GPT. Here I use LangChain to access
a PDF on my filesystem (a sample pen test report) and ask GPT to summarize the
document.
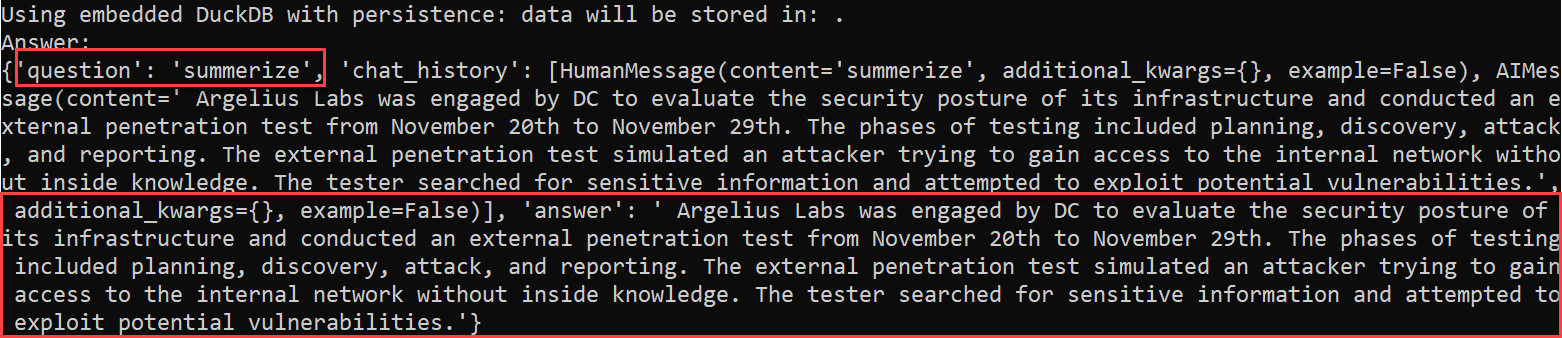
Ok, this is cool! We just used GPT to summarize a ten-page PDF. Lets try to use ChatGPT to analyze a larger file.

And now we see that while we’ve given GPT access to websites and files, we still have a limitation on how much data it can ingest. The good news is that we have a solution to that too. There’s one more item we’re going to add to our LangChain model, the AI database.

First, let’s take a second to explain why I’m saying AI database instead of just database. A normal database is designed to store and share data. Exact data. If I give a database 50,000 words of text, I expect it to store all 50,000 words. With an AI database, it tries to summarize concepts from those 50,000 words and turn those concepts into numerical values. That sounds wild, but let’s look at things in a less technical way.
Imagine you have a group of 4 friends hanging out. You’ve
known each other for years and hang out regularly. Now a 5th person is
coming over for the first time. You know them, but they don’t know the other 4.
When the new person comes over, you won’t spend hours explaining
to them who the other four visitors are; you’ll summarize. You’ll provide their
name, maybe where they work, how long you’ve known them, a hobby or an interesting
fact or two, and move on. That’s what an AI database does as well. This concept is known as embeddings and is
weird at first, but it is an extremely efficient way to deal with massive
amounts of information.
So now, what we do is modify our Python code to use an AI
database to summarize our information and provide that to GPT for background
context to answer our prompts. There are multiple options we could choose for
our database, including online options, such as Pinecone, and local options
including Chroma.
Here we modify our Python code to use Chroma in ingesting a 387-page
PDF book on using Python to program video games.

We then provide that information to GPT and ask it to summarize the book. Second later, we have a response.

I’ve said multiple times that I think the most under-appreciated capability of large language models like ChatGPT is the ability to summarize, and this unlocks that capability to a whole new world of data.
There’s a lot more to LangChain than we’ve covered here. It
can work with numerous data sources and other LLMs. Since we’re using the GPT
API, there is a small fee associated with each request. Running all of the examples
for this blog post, including the 378-page PDF, cost less than $0.30.
In part two of this blog series, we’ll look at the Python
code and how you can get it up and running.

Comments
Post a Comment